179
53
2,127
200.83
The winners of the PRC Data Challenge 2025 are determined by the criteria below.
All public eligible final repository forks are live on the PRC Data Challenge 2025 GitHub page.
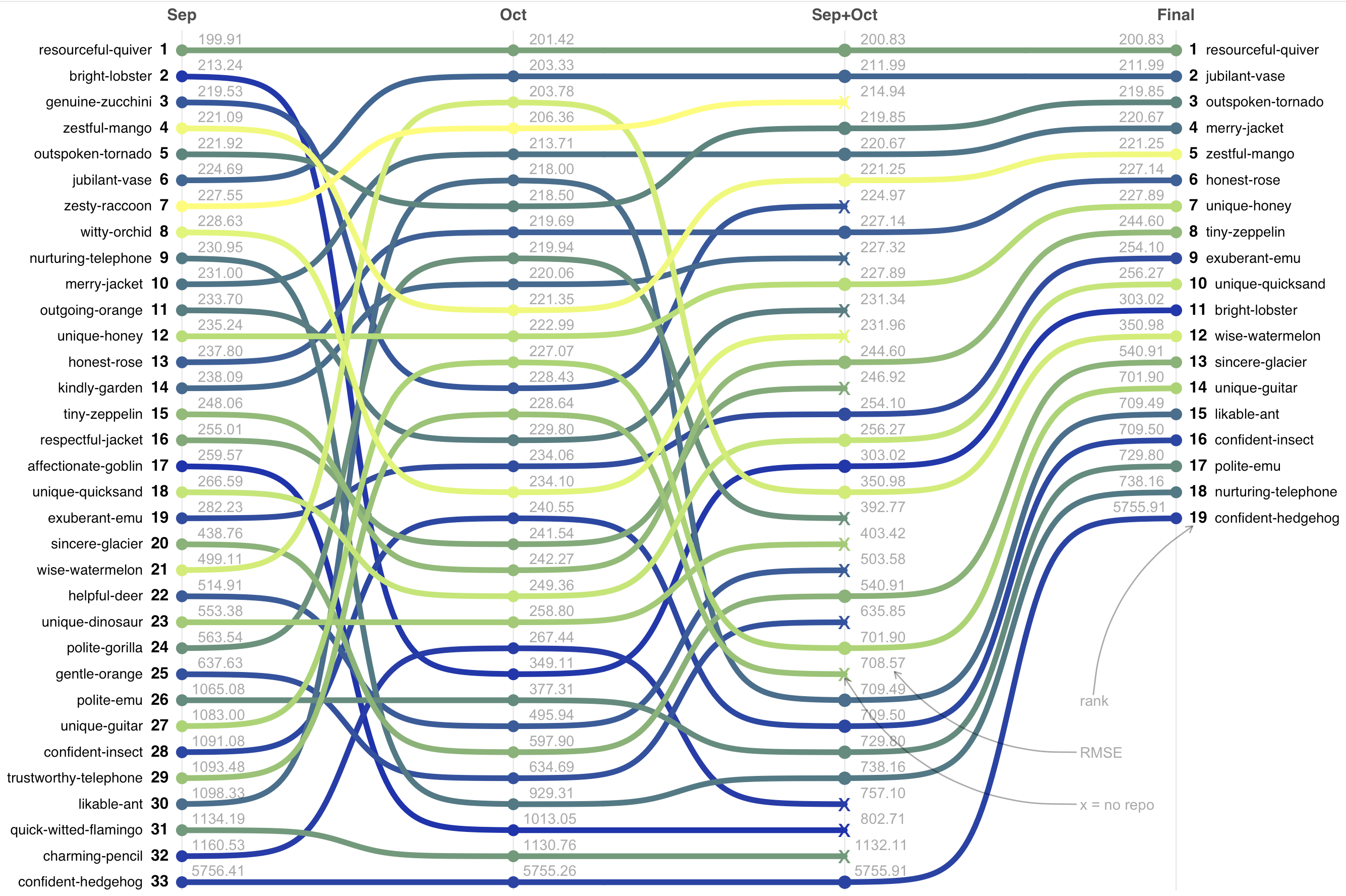
| Place | Team | RMSE | Prize |
|---|---|---|---|
| 1 | resourceful-quiver | 200.83 | 2500 EUR |
| 2 | jubilant-vase | 211.99 | 1750 EUR |
| 3 | outspoken-tornado | 219.85 | 750 EUR |
Congratulations!
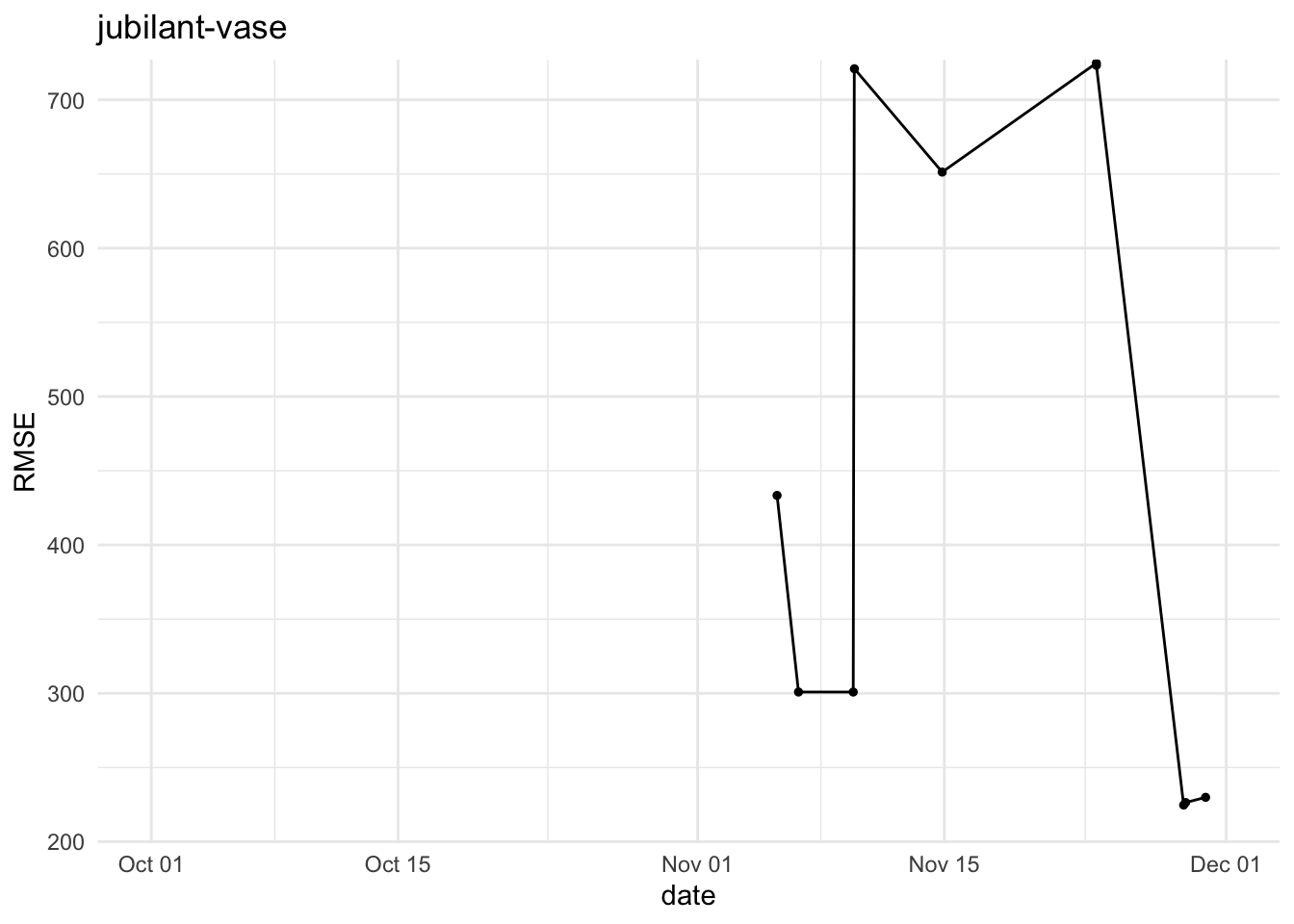
To get an overview of the competition, the plot below shows how each team scored for the different data intervals of the submission for the final phase of the challenge.
We used the <team-name>_final.parquet submission, and calculated the RMSE for the September intervals (Sep), October intervals (Oct) and the whole September and October intervals (Sep+Oct).
You reach the Final only if you shared the (documented) code and docs in a Github repository.
Lower RMSE scores reflect better performance.
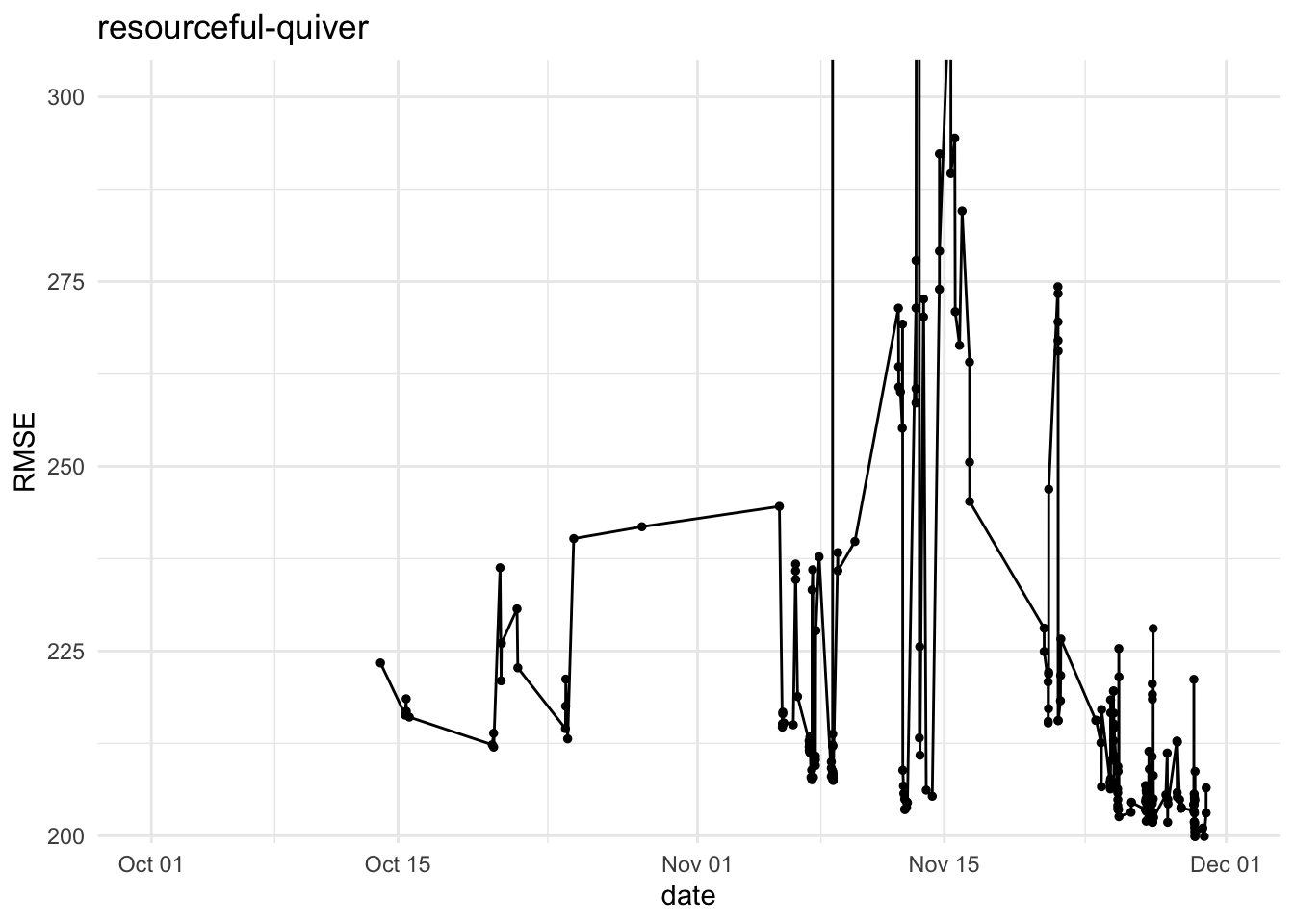
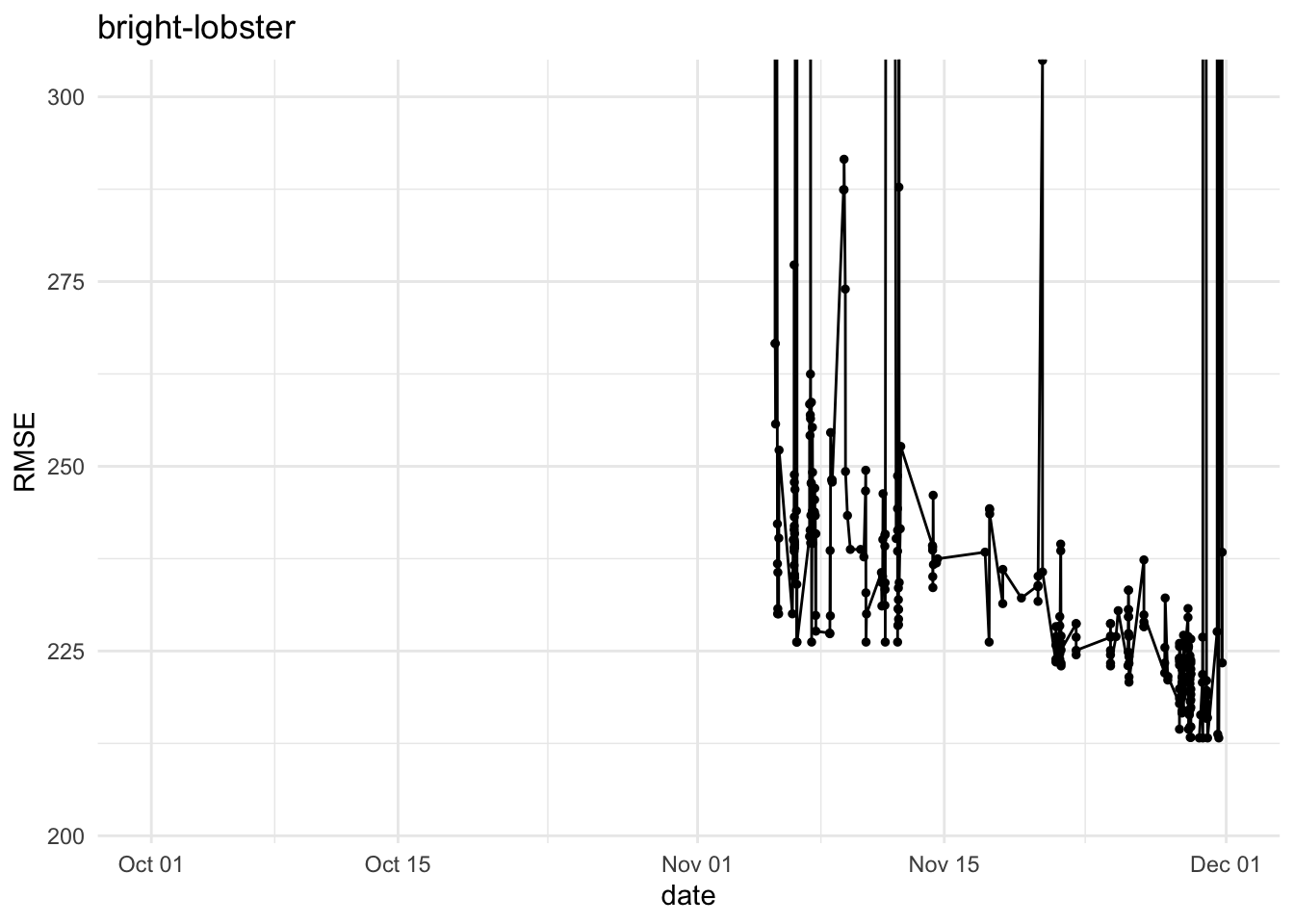
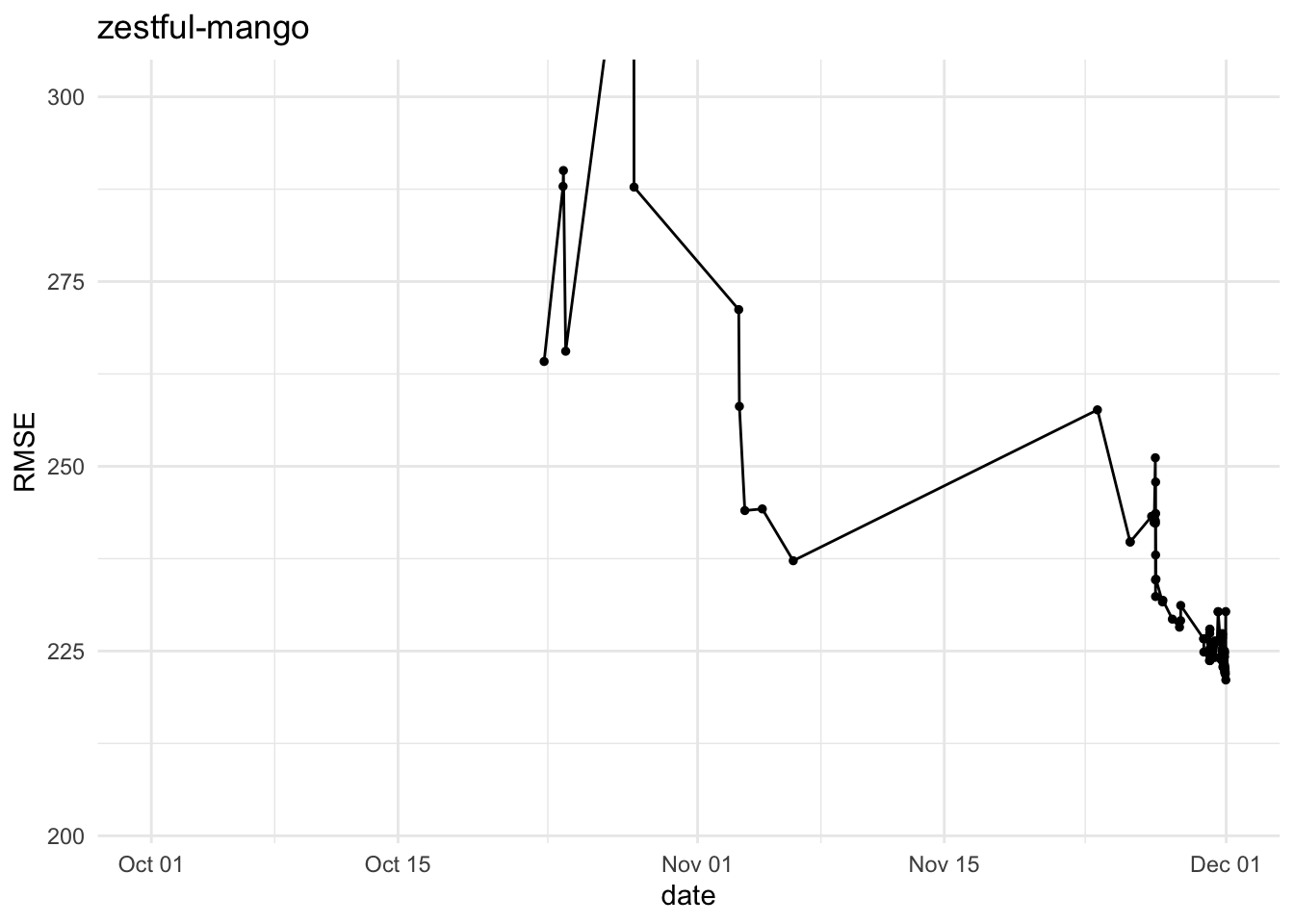
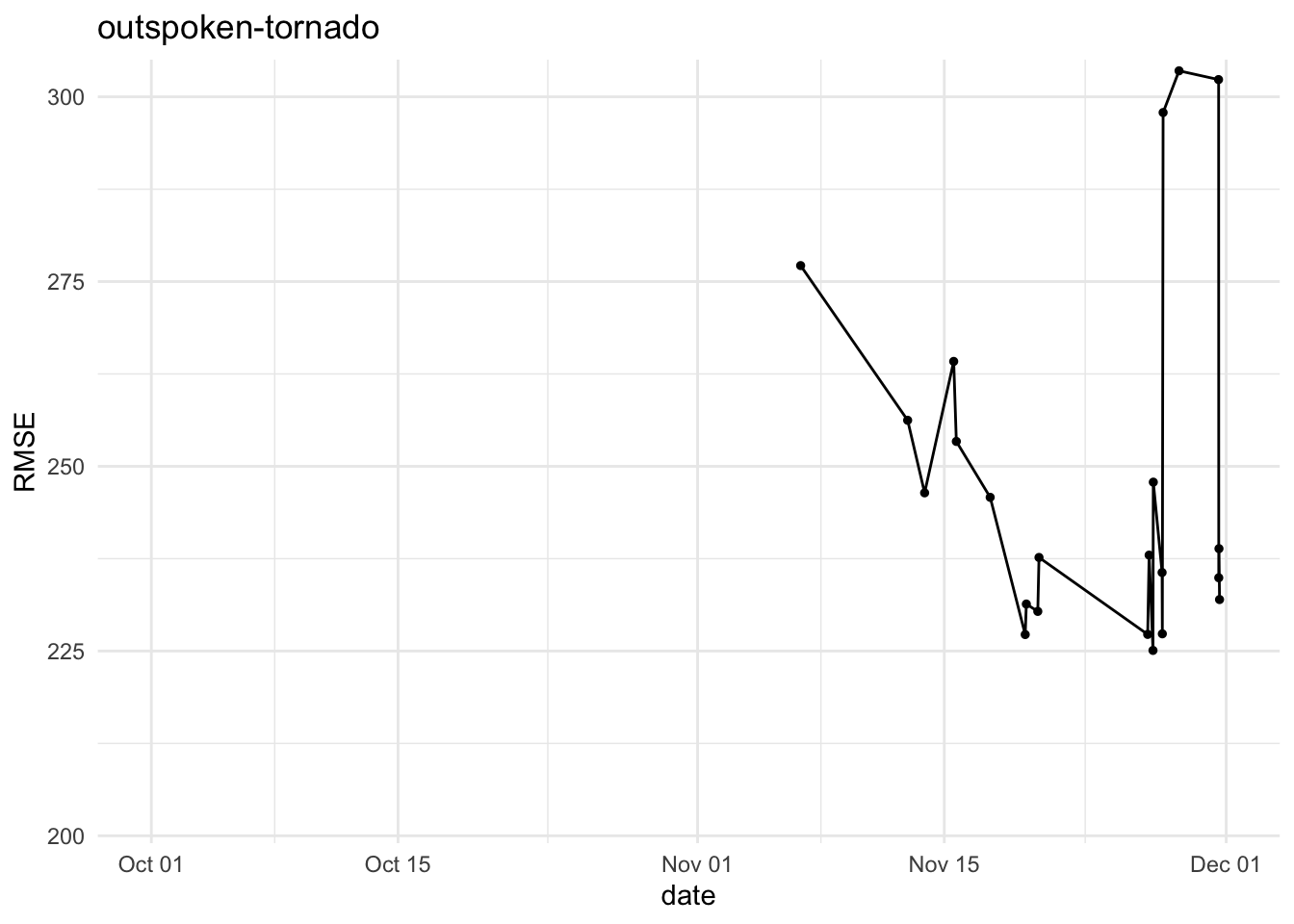
Inspired by an exchange with team genuine-zucchini, below are refreshed RMSE histories for five teams for phase 1 submissions, i.e. team-name_vY.parquet. They highlight where big swings happened during the final phase.
It would be nice to dig into the commits and see which experiments were linked to the jumps in RMSE…this is left as an exercise for the readers 😇 (or as a suggestion to the authors to write more about their attempts at improving the RMSE).
In the following sections we summarize the review of the repo for each team for the top RMSE < 400. Order is by the final rank.
The submission by resourceful-quiver presents a well-founded and thoughtful methodology that is strongly informed by domain knowledge rather than relying exclusively on machine-learning techniques. In particular, the team effectively leverages insights from last year’s competition, notably the mass estimator approach, to model ATOW. This grounding in prior work and physical understanding strengthens the credibility and robustness of the overall modeling strategy.
From a technical perspective, the feature engineering is advanced and carefully designed, demonstrating a clear understanding of the problem context. A notable contribution is the custom extension developed for the traffic library to handle data cleaning, which is both elegant and effective. While the Jupyter notebooks contain relatively sparse commentary, the Python scripts and modules are sufficiently documented to remain understandable for an informed reader.
Documentation is a major strength of this submission. The near-complete JOAS-style paper is clearly written, well structured, and provides an excellent description of the approach, methodology, and results. Although the code itself is (sometimes) sparsely documented, it remains readable and coherent, benefiting from strong conceptual clarity and domain expertise. Overall, this is a high-quality, resourceful submission that sets a strong benchmark for the challenge.
The submission by jubilant-vase demonstrates a solid and well-structured technical approach informed by domain knowledge and prior experience from last year’s challenge. The team adopts a mass estimation strategy consistent with the previous competition and combines it with an ensemble of three gradient boosting libraries, resulting in a robust and competitive modeling framework. The overall codebase is cleanly organized, reflecting good software engineering practices.
Documentation is distilled but generally effective. The scripts are well structured, and many functions are clearly documented, although the level of detail is somewhat uneven across the codebase. While there is no accompanying paper describing the methodology and the README appears auto-generated(?), the clarity of the code itself compensates to a large extent. Overall, this is a strong second-place submission with a sound methodological foundation and solid implementation quality.
The submission by outspoken-tornado follows a predominantly machine-learning–driven approach, with less emphasis on domain-specific feature engineering. The extracted features focus mainly on trajectory-derived statistics such as mean and maximum true airspeed and mean vertical rate. While these features are reasonable, there is limited evidence of domain-informed validation, such as checks for outliers or physically implausible values, which may affect model robustness.
From a software engineering standpoint, the codebase is highly structured, possibly to the point of being over-structured. The team developed a dedicated prc_challenge module to handle preprocessing and feature engineering, which does cleanly separates concerns and centralizes the main data-processing logic. Although the overall organization is clear and systematic, the lack of more domain-specific feature design limits the distinctiveness of the methodological contribution.
The merry-jacket submission presents a clear but relatively brief README and employs an ensemble of two models to address the task. While some domain- and aircraft-type–specific features are included, the absence of a dedicated TOW estimation step and more advanced feature limits the overall methodological depth.
The zestful-mango submission includes some code comments, primarily in Spanish, but provides limited explanation of design choices and feature selection rationale. With a final commit on 1 December, the overall approach appears functional but lacks sufficient documentation to clearly convey the methodological intent.
The honest-rose submission provides a well-written PDF describing the progressive addition of features and the rationale behind them, including exploratory use of weather and economic variables, which were ultimately found to have limited influence. However, the absence of TOW estimation, missing referenced data files, hardcoded paths, and sparse code documentation—particularly in the R scripts—limit reproducibility and overall robustness.
The unique-honey submission features a well-structured and informative README, includes links to external data sources, and applies sound data-cleaning practices such as removing outliers and unrealistic values, followed by an ensemble modeling approach. However, the rationale behind feature engineering choices is only briefly discussed, and the use of flight phases largely mirrors approaches seen in other submissions rather than introducing distinct methodological insights.
The tiny-zeppelin submission offers limited guidance on how to run or reproduce the workflow, with the orchestrator appearing to be the main entry point, and relies on hardcoded Windows-specific paths that hinder portability. Sparse code comments, limited justification for design and feature choices, and a largely standard use of flight phases reduce the clarity and reproducibility of the approach.
The exuberant-emu submission relies on hardcoded paths and provides limited explanation of modeling choices or feature engineering decisions. The approach is predominantly machine-learning–driven, with only basic, weakly domain-specific features such as mean or standard deviation of vertical rate and mean Mach number.
The unique-quicksand submission provides a thoughtful analysis of noise in the data and follows a sensible modeling progression, starting from a simple baseline before experimenting with xgboost. Although the more complex model did not outperform the baseline, the decision to retain the more robust initial model for the final submission reflects sound judgment.
The bright-lobster submission stands out for its strong emphasis on reproducibility, excellent documentation, and a well-defined entry point, supported by cleanly organized and well-commented Python code. The team demonstrates deep domain awareness through TOW estimation, use of METAR data, passenger statistics, SkyVector airport information, domain-specific features, and data augmentation via Gaussian noise for widebody aircraft.
The wise-watermelon submission consists solely of two Python notebooks with no accompanying documentation or in-code comments. The lack of explanatory material makes it difficult to understand, assess, or reproduce the approach despite the simplicity of the setup.